-
Siren’s Song in the AI Ocean:A Survey on Hallucination in Large Language Models논문 리뷰 2024. 7. 2. 17:47반응형
2024.07.02 - [논문 리뷰] - llm-hallucination-survey
Abstract
대형 언어 모델(LLMs)은 다양한 다운스트림 작업에서 놀라운 능력을 입증했지만, 이 모델들이 환각을 나타내는 경향이 있다는 중요한 문제가 제기되고 있다. LLMs는 때때로 사용자 입력과 일치하지 않거나, 이전에 생성된 컨텍스트와 모순되거나, 확립된 세계 지식과 일치하지 않는 내용을 생성한다. 이러한 현상은 실제 시나리오에서 LLMs의 신뢰성에 상당한 도전을 제기한다. 이 논문에서는 LLM의 환각을 탐지, 설명 및 완화하는 최근의 노력을 조사하고, LLM이 직면하는 독특한 문제에 중점을 둔다. 우리는 LLM 환각 현상의 분류와 평가 벤치마크를 제시하고, LLM 환각을 완화하기 위한 기존 접근법을 분석하며, 향후 연구 방향에 대한 잠재적 방안을 논의한다.
Introduction
대형 언어 모델(LLMs)은 특히 많은 수의 파라미터로 특징지어지며 자연어 처리(NLP)와 인공지능(AI) 개발의 유망한 초석으로 부상했습니다(Zhao et al., 2023c). 지도 학습 미세 조정(SFT; Zhang et al., 2023b) 및 인간 피드백을 통한 강화 학습(RLHF; Ouyang et al., 2022; Fernandes et al., 2023)과 같은 적절한 정렬 기법을 통해 최근의 LLMs(OpenAI, 2023a; Touvron et al., 2023b; OpenAI, 2023b 등)은 다양한 다운스트림 작업을 해결하는 데 강력한 능력을 보여주었습니다.
그럼에도 불구하고, 그림 1에서 예시된 바와 같이, LLMs는 놀라운 성공에도 불구하고 사용자 입력(Adlakha et al., 2023), 이전에 생성된 컨텍스트(Liu et al., 2022) 또는 사실적 지식(Min et al., 2023; Muhlgay et al., 2023; Li et al., 2023a)에서 벗어나는 출력을 생성하는 경우가 있습니다. 이러한 현상은 일반적으로 환각이라고 하며, 실제 시나리오에서 LLMs의 신뢰성을 크게 저하시킵니다(Kaddour et al., 2023). 예를 들어, LLMs는 잘못된 의료 진단이나 치료 계획을 만들어 실제 생활에서의 위험을 초래할 수 있습니다(Umapathi et al., 2023).
기존의 자연어 생성(NLG) 설정에서 환각 현상은 널리 연구되었지만(Ji et al., 2023), LLMs 영역 내에서 환각 문제를 이해하고 해결하는 것은 다음과 같은 독특한 도전 과제를 포함합니다:
- 방대한 훈련 데이터: 특정 작업을 위해 데이터를 신중하게 큐레이팅하는 것과 달리, LLM 사전 훈련은 웹에서 얻은 수조 개의 토큰을 사용하므로 허위, 구식 또는 편향된 정보를 제거하기 어렵습니다.
- LLMs의 다재다능성: 범용 LLMs는 작업 간, 언어 간 및 도메인 간 설정에서 뛰어나야 하므로 환각의 포괄적인 평가 및 완화에 도전 과제가 됩니다.
- 오류의 인지 불가능성: 강력한 능력의 부산물로서 LLMs는 초기에는 매우 그럴듯해 보이는 허위 정보를 생성할 수 있어 모델이나 인간이 환각을 감지하기 어렵습니다.
추가적으로, RLHF 과정(Ouyang et al., 2022), 모호한 지식 경계(Ren et al., 2023) 및 LLMs의 블랙박스 특성(Sun et al., 2022)도 LLMs에서 환각을 감지, 설명 및 완화하는 것을 복잡하게 만듭니다.
앞서 언급한 도전 과제를 해결하기 위한 최첨단 연구가 눈에 띄게 증가하고 있으며, 이는 이 설문 조사를 작성하는 강력한 동기를 제공합니다.
본 논문은 다음과 같이 구성됩니다. 그림 2에서도 설명된 바와 같이, 먼저 LLMs의 배경을 소개하고 LLMs에서의 환각에 대한 정의를 제공합니다(§2). 다음으로 관련 벤치마크와 메트릭스를 소개합니다(§3). 이후 LLM 환각의 잠재적 원천을 논의하고(§4), 문제를 해결하기 위한 최근 작업을 심도 있게 검토합니다(§5). 마지막으로 향후 전망을 제시합니다(§6). 관련 오픈 소스 자료는 지속적으로 업데이트되며, https://github.com/HillZhang1999/llm-hallucination-survey에서 접근할 수 있습니다.
Zhang, Yue, et al. "Siren's song in the AI ocean: a survey on hallucination in large language models." arXiv preprint arXiv:2309.01219 (2023).
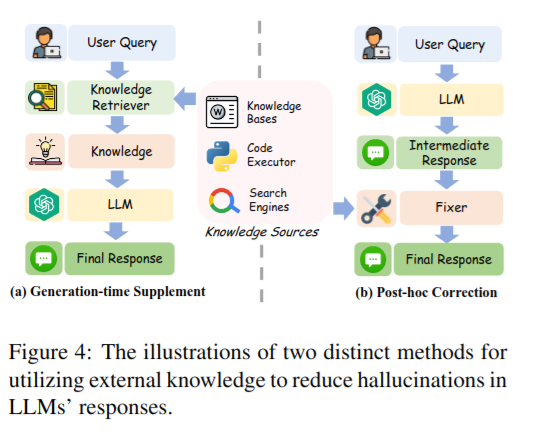
There is no need to modify LLMs, making it a plug-and-play efficient solution. It enables easy transfer of unique knowledge (e.g., the company's internal data) and real-time updated information to LLMs. Finally, this approach improves the interpretability of information generated by LLMs by allowing the results to be traced back to source evidence.
요약 및 정리
강력한 이해 및 생성 능력을 갖춘 LLMs는 학계와 산업계 모두에서 큰 주목을 받고 있습니다. 그러나 환각은 LLMs의 실용적 응용을 방해하는 중요한 과제로 남아 있습니다. 이 설문조사에서는 주로 ChatGPT 출시 이후의 최신 발전을 포괄적으로 검토하여 LLMs 내 환각을 평가, 추적 및 제거하는 것을 목표로 합니다. 또한, 기존의 도전 과제를 탐구하고 잠재적인 향후 방향을 논의합니다.
LLMs are gaining significant attention in academia and industry due to their strong understanding and creation capabilities. However, hallucinations pose a significant challenge that hinders their practical application. The proposed research aims to evaluate, track, and eliminate hallucinations in LLMs by comprehensively reviewing the latest developments since the launch of ChatGPT.
반응형'논문 리뷰' 카테고리의 다른 글
ALMA: Alignment with Minimal Annotation (0) 2025.04.10 Do Language Models Know When They’re Hallucinating References? (0) 2024.05.27 Rethinking STS and NLI in Large Language Models (0) 2024.05.27 What makes Chain-of-Thought Prompting Effective? A Counterfactual Study (0) 2024.05.27 Attribute First, then Generate:Locally-attributable Grounded Text Generation (0) 2024.05.23