-
LLaVA / LLaVA-NeXT논문 리뷰/Multimodal 2025. 1. 15. 14:49반응형
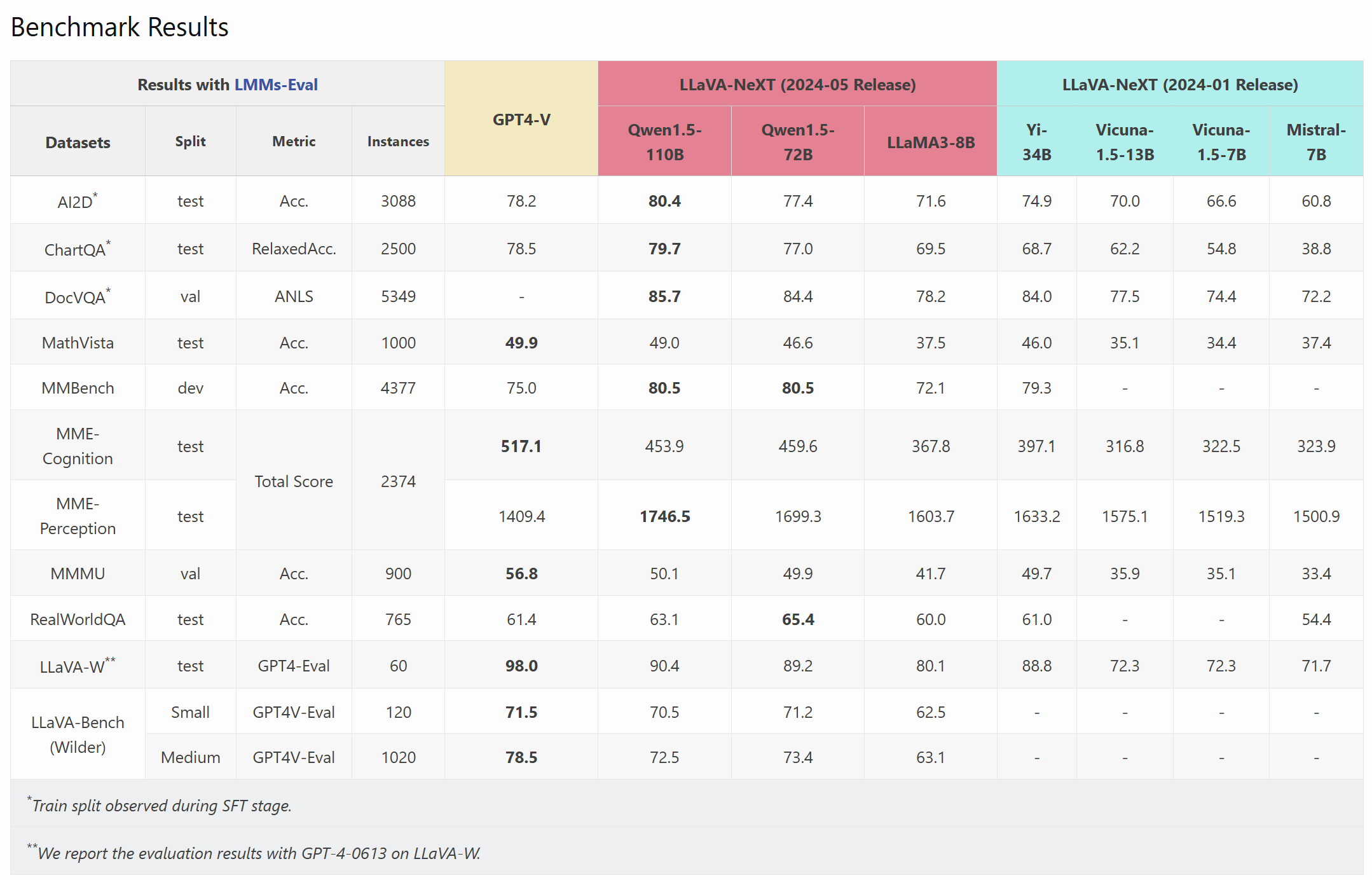
https://github.com/LLaVA-VL/LLaVA-NeXT
GitHub - LLaVA-VL/LLaVA-NeXT
Contribute to LLaVA-VL/LLaVA-NeXT development by creating an account on GitHub.
github.com
참고 블로그>
LLaVA NeXT: 제미나이 프로를 뛰어넘는 오픈소스 멀티모달 AI!
안녕하세요! 오늘은 멀티모달 대규모 언어 모델 LLaVA의 업데이트 소식에 대해 알아보겠습니다. LLaVA (Language-Image Visual Assistant, 언어-이미지 시각 어시스턴트)는 시각적 지시 조정기술(Visual Instructi
fornewchallenge.tistory.com
llava 1.5>
https://phd-frog.tistory.com/4
[LLaVA 1.5] Improved Baselines with Visual Instruction Tuning
Link: https://arxiv.org/pdf/2310.03744.pdf프로젝트 링크: https://llava-vl.github.io/깃허브: https://github.com/haotian-liu/LLaVA0. Abstract대형 멀티모달 모델 (LMM, Large Multimodal Models)는 최근 시각적인 instruction 튜닝에서
phd-frog.tistory.com
[논문 리뷰] Visual Instruction Tuning | LLaVA Model
💡 LLaVA 1. 연구 주제와 주요 기여 이 연구는 텍스트와 이미지를 함께 이해하고 처리할 수 있는 멀티모달 모델 LLaVA를 제안하고 있어요. 특히 Visual Instruction Tuning을 통해 멀티모달 작업에서 사
mvje.tistory.com
https://velog.io/@jk01019/Improved-Baselines-with-Visual-Instruction-Tuning
Improved Baselines with Visual Instruction Tuning
https://arxiv.org/pdf/2310.03744https://velog.io/@jk01019/Visual-Instruction-TuningLMM(Large Multimodal Model) 중 하나인 LLaVA에 대한 간단한 수정을 통해 성능
velog.io
https://kyujinpy.tistory.com/157
[LLaVA-NeXT 논문 리뷰] - Improved Baselines with Visual Instruction Tuning
*LLaVA-NeXT를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! LLaVA-Next Github: https://github.com/LLaVA-VL/LLaVA-NeXT GitHub - LLaVA-VL/LLaVA-NeXTContribute to LLaVA-VL/LLaVA-NeXT development by creating an account on
kyujinpy.tistory.com
반응형'논문 리뷰 > Multimodal' 카테고리의 다른 글