-
“According to . . . ”: Prompting Language ModelsImproves Quoting from Pre-Training Data논문 리뷰/Prompt engineering 2024. 5. 22. 16:07반응형

초록
더보기대형 언어 모델(LLM)은 사실적인 데이터로 사전 학습을 했음에도 불구하고 환각을 일으키고 가짜 정보를 생성할 수 있습니다. 저널리즘 장치인 “출처에 따르면”을 참고하여, 우리는 LLM이 이전에 관찰된 텍스트를 기반으로 응답을 유도하는 "출처에 따른 프롬프트"를 제안합니다. 이 기반을 정량화하기 위해, 우리는 모델이 생성한 답변이 기본 텍스트 자료에 얼마나 직접적으로 나타나는지를 측정하는 새로운 평가 지표 (QUIP-Score)를 제안합니다. 우리는 세 가지 자료 (위키백과, PubMed, 미국 법률 세법)에 대한 실험을 통해 이러한 프롬프트가 우리의 지표 하에서 기반을 개선함을 보여주며, 추가적인 이점으로 종종 최종 과제 성능이 향상됨을 보여줍니다. 더욱이, 모델에게 기반을 줄이거나(또는 다른 자료에 기반을 두도록) 요청하는 프롬프트는 실제로 QUIP-Score를 감소시키며, LLM이 요청에 따라 기반 생성을 증가 또는 감소시킬 수 있는 능력을 나타냅니다.
1. Introduction
더보기대형 언어 모델(LLM)의 실사용 애플리케이션 배포가 계속 증가함에 따라, 거짓 콘텐츠를 생성하는 경향은 다운스트림 사용자에게 상당한 위험을 초래합니다(Ji et al., 2022). 최근 연구는 검색 기능을 추가하여 이 문제를 해결하려고 시도했습니다(Shuster et al., 2021; Sun et al., 2023; Borgeaud et al., 2022); 그러나 이러한 모델은 실제로 환각 문제를 여전히 겪고 있습니다(Liu et al., 2023).
이 연구는 LLM이 사전 학습 중에 기억한 큐레이션된 정보 소스를 더 많이 인용하도록 유도함으로써 거짓 정보를 생성하는 경향을 줄이는 흥미로운 가능성을 탐구합니다. 그림 1에서와 같이, "위키백과에 따르면"과 같은 구문을 추가하면 LLM이 사전 학습 코퍼스에 포함되었을 것으로 추정되는 위키백과에서 인용하도록 유도할 수 있는지 여부를 탐구합니다. 우리는 현재의 LLM(오픈 소스 및 클로즈드 소스 모두)을 사용하여 이것이 가능하다는 실증적 증거를 발견했습니다.
우리의 연구는 두 가지 최근 연구 영역에서 영감을 받았습니다. 첫째, 더 큰 LLM은 자연어 프롬프트를 사용하여 더 효과적으로 안내할 수 있습니다(Ouyang et al., 2022; Wan et al., 2023; Ganguli et al., 2023). 둘째, LLM이 커질수록 사전 학습에서 사실과 진술을 기억하는 능력이 향상됩니다(Kandpal et al., 2022; Tirumala et al., 2022; Carlini et al., 2023, 2020). 따라서 우리는 LLM이 기억을 긍정적인 목적으로 사용하도록 유도하여 보다 근거 있는 출력을 생성하고자 합니다.
이 연구의 핵심 단계는 생성된 출력이 사전 학습 데이터와 상당히 겹치는지 여부를 신속하게 결정하는 것입니다. 즉, DATA PORTRAIT(Marone and Van Durme, 2023)를 통해 효율적으로 멤버십 테스트를 수행하는 것입니다. 우리는 DATA PORTRAIT의 속도와 효율성을 활용하여 QUIP-Score(Quoted Information Precision)라는 새로운 지표를 설계했습니다. QUIP-Score는 n-그램 중복을 계산하여 문장의 일부가 코퍼스에 정확히 포함된 정도를 정량화합니다.
"출처에 따른 프롬프트"를 설명하기 위해, 우리는 오픈 도메인 질문 응답(ODQA) 작업을 기반으로 실험을 수행하며, 여기서 출처에 근거한 답변이 특히 중요합니다. 우리는 목표 코퍼스(위키백과, PubMed, 미국 법률 세법)에 근거한 정보를 향하도록생성을 유도하는 인간 작성 프롬프트를 수집했습니다. 모든 인간 작성 프롬프트에서 선택한 코퍼스와의 중복을 5-105% 증가시키면서도 다운스트림 성능을 유지하거나 개선할 수 있음을 관찰했습니다. 우리는 다양한 데이터셋과 모델(오픈 소스 및 클로즈드 소스 LLM 포함)에 걸쳐 결과를 보여줍니다.
흥미롭게도, 반대 현상도 관찰되었습니다. LLM이 기반을 두지 않도록 하거나 다른 코퍼스에 기반을 두도록 유도하는 프롬프트를 통해 LLM이 기반을 두는 것을 억제할 수 있습니다. 예를 들어, 위키백과와의 중복을 감소시키면서 위키백과 콘텐츠에 의존하는 다운스트림 작업의 성능을 낮출 수 있음을 발견했습니다.
우리는 다양한 모델 크기에 대한 확장 실험을 수행했으며, 크기가 커질수록 제안된 접근법의 효과도 증가한다는 것을 확인했습니다. 이는 지시를 따르는 LLM의 추가 확대로 환각이 감소할 수 있음을 시사합니다.
요약하면, 우리는 LLM이 보다 사실적인 정보를 생성할 수 있는 능력을 향상시키기 위한 간단하고 효과적인 접근법인 "출처에 따른 프롬프트"를 제시합니다. 또한, 사전 학습 코퍼스에 대해 LLM 생성의 기반성을 측정하기 위한 효율적인 지표인 QUIP-Score를 소개합니다. 우리는 다양한 프롬프트 전략을 모델, 데이터셋 및 확장 경향에 걸쳐 실험했으며, "출처에 따른" 방법이 도입된 지표 하에서 일관되게 기반성을 향상시킴을 발견했습니다.

3. Methodology
더보기Defining Grounding
커뮤니티에는 기반(grounding)에 대한 다양한 정의가 있습니다(Bohnet et al., 2022; Mallen et al., 2023). 이 용어의 광범위한 범위를 인정하면서도, 우리는 좁은 정의를 채택합니다. 우리는 생성된 텍스트가 코퍼스에서 정확한 인용일 경우 이를 기반으로 정의합니다. 이는 어휘 형태가 일치하지 않을 때 의미적 기반을 포함하지 않기 때문에 일부 정의보다 더 엄격합니다. 그러나 인용은 직관적이고 측정하기 간단한 기반의 한 형태입니다. 따라서 우리는 인용과 기반을 서로 교환하여 사용합니다.
(we use quoting and grounded interchangeably)
3.1 QUIP-Score: Measuring Grounding to Pre-Training Data
모델 사전 학습 데이터에서 기반 및 인용을 이해하려면 인용을 측정할 지표가 필요합니다. 직관적인 접근 방식은 LLM의 생성물에서 찾은 n-그램을 코퍼스에 있는 것과 비교하는 n-그램 측정법을 사용하는 것입니다. 이러한 인용 지표는 대규모 참조 코퍼스로 확장할 수 있도록 효율적이어야 합니다.
Problems with existing N-gram metrics
BLEU 또는 ROUGE와 같은 기존 n-그램 지표는 참조에서 n-그램의 수를 저장합니다. 그러나 수를 저장하는 것은 위키백과와 같은 대규모 코퍼스에 대해 데이터 구조(예: 기존 해시 테이블)를 사용하는 것을 필요로 하며 이는 계산적으로 어렵습니다. 우리는 Wikipedia를 참조로 사용하여 sacrebleu(Post, 2018)를 단순히 확장하면 약 1.5TB의 RAM을 소비할 것으로 추정합니다(부록 C).
QUIP-Score
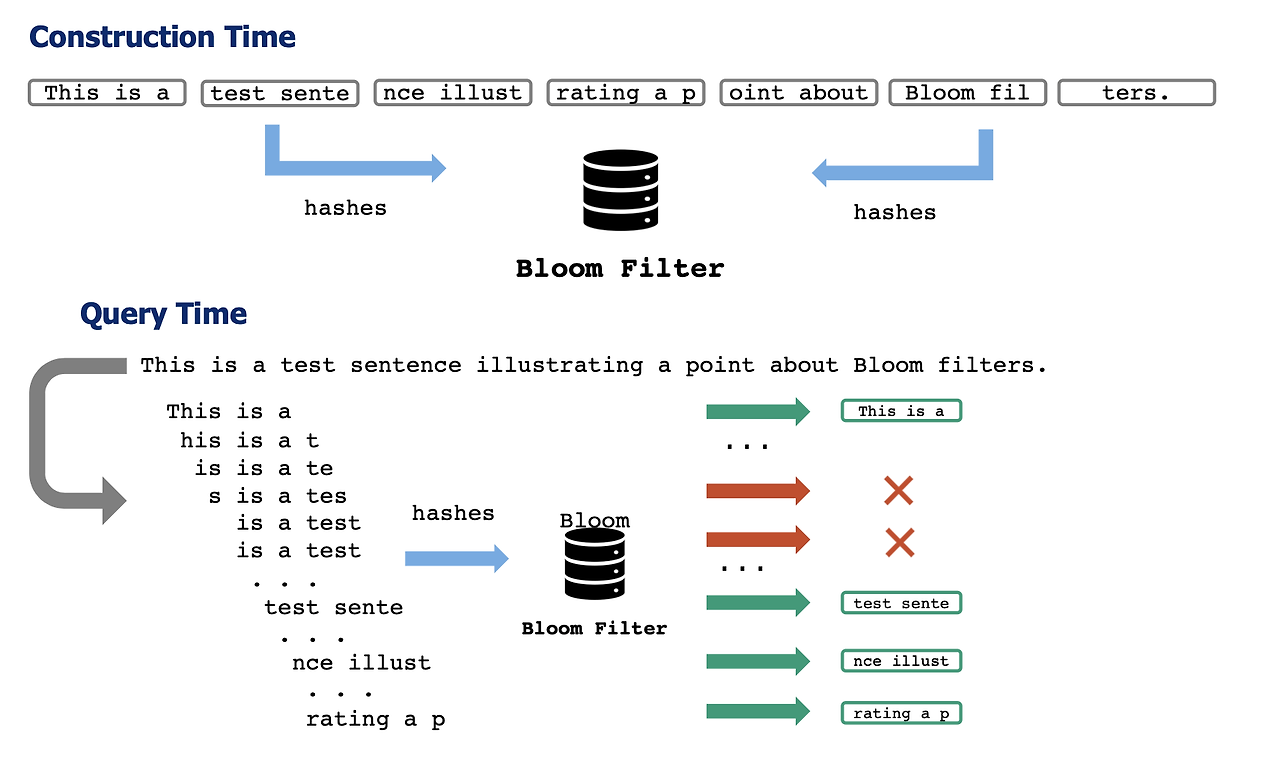
사전 학습 데이터에서 인용을 효율적으로 측정하기 위해, 우리는 Bloom 필터 기반의 DATA PORTRAIT(Marone 및 Van Durme, 2023)에서 시작합니다. 이는 해시 테이블을 사용하여 수를 저장하는 방법보다 더 빠르고 메모리 효율적인 불리언 멤버십 쿼리를 허용합니다. Bloom 필터 접근법은 큰 코퍼스를 일회성으로 인덱싱하고 상수 시간 조회를 가능하게 합니다.
우리는 생성된 출력과 사전 학습 코퍼스 간의 문자 n-그램 정밀도를 QUIP-Score라는 새로운 지표로 정의합니다. 더 구체적으로, 생성물 Y와 텍스트 코퍼스 C에 대해:

여기서 1(.)은 DATA PORTRAIT로 구현된 지시 함수입니다. gramn ∈ C이면 1, 아니면 0입니다. 따라서 0.5의 점수는 생성된 텍스트 n-그램의 50%가 사전 학습 코퍼스에 포함되어 있음을 나타냅니다. 우리는 주어진 테스트 데이터셋에 대한 단일 성능 수치를 얻기 위해 여러 생성에 걸쳐 이 양을 매크로 평균화합니다.
QUIP-Score Implementation
우리는 Pile에 포함된 위키피디아 버전을 기반으로 DATA PORTRAIT를 구축합니다. 이는 GPT-J와 같은 많은 모델에 포함된 사전 학습 데이터를 정확히 테스트할 수 있게 해줍니다(다른 코퍼스에 QUIP-Score를 적용한 실험은 §6을 참조하세요). 서로 다른 모델이 서로 다른 토큰화 방식을 사용하기 때문에 토큰 기반보다는 문자 기반 n-그램을 사용합니다. 또한, 문자 기반 n-그램 지표는 chrF/chrF++와 같은 지표를 사용하여 기계 번역에서 널리 사용됩니다(Popović, 2015, 2017). 우리는 스케치6에 대해 25자의 n-그램(약 5단어)을 선택했으며, 이는 실험적으로 의미 있는 결과를 제공함을 발견했습니다(너무 작지도 크지도 않은 n-그램). DATA PORTRAIT가 정확한 일치를 확인하기 때문에 철자 변형(예: 대소문자, 공백)에 민감하다는 점에 유의하십시오. 우리는 QUIP-Score를 실제 인용 성능의 하한으로 간주합니다.
3.2 Validity of QUIP-Score
QUIP-Score는 n-그램 지표이므로 BLEU 및 ROUGE와 같은 확립된 지표의 많은 특성을 계승합니다. 또한, 많은 이전 연구에서는 더 높은 기반과 더 적은 환각 사이의 연결을 확립했습니다(§2). 이러한 이전 연구를 기반으로, 우리는 QUIP-Score가 (1) 다른 n-그램 지표와 마찬가지로 인용을 정확하게 측정하고 (2) 환각이 적은 것과 상관관계가 있음을 확립합니다.
먼저 간단한 실험을 수행합니다: 완전히 인용된 문서(예: 정확한 위키백과 페이지)와 반드시 인용이 아닌 문서(예: Pile에서 가져온 문서)를 측정할 때 QUIP-Score는 무엇일까요? 각각에서 무작위로 1000개의 문서를 샘플링합니다. 위키백과 문서의 평균 QUIP-Score는 99.9%이며 표준 편차는 0.1%인 반면, Pile에서는 17.0% ± 0.8%입니다. 따라서 QUIP-Score가 완전한 인용을 정확히 측정하고 랜덤 텍스트는 약 17%의 QUIP-Score를 갖는다는 것을 알 수 있습니다.
다음으로, 우리는 NQ에서 LLM 생성에서 발견된 부분적, 맥락적 인용을 고려합니다. QUIP-Score 범위별로 생성을 나누고 각 범위에서 50개를 샘플링합니다. 그런 다음 두 가지 수동 분석을 수행합니다: (1) 생성물의 얼마나 많은 부분이 인용인지(없음, 일부, 대다수, 또는 모두/거의 모두)와 (2) 생성물이 환각인지 여부(확실하지 않은 경우 골드 출처 및 답변, 구글 검색을 사용). 표 1은 QUIP-Score가 증가함에 따라 인용의 양이 증가하고 환각의 양이 감소함을 보여줍니다.
이 결과는 n-그램 지표에 대한 많은 문헌(Belz and Reiter, 2006; Reiter and Belz, 2009; Popović, 2015) 및 기반과 환각에 대한 문헌(Lazaridou et al., 2022; Borgeaud et al., 2022; Andriopoulos and Pouwelse, 2023)에서 이미 입증되었기 때문에 놀라운 일이 아닙니다. 그러나 이 분석은 기반을 위한 인용 사용과 n-그램 지표로서 QUIP-Score를 사용하는 것이 이러한 바람직한 속성을 유지한다는 것을 실증적으로 보여줍니다.
DATA PORTRAIT
더보기Data portraits: Recording foundation model training data
https://github.com/ruyimarone/data-portraits
GitHub - ruyimarone/data-portraits: Documenting large text datasets 🖼️ 📚
Documenting large text datasets 🖼️ 📚. Contribute to ruyimarone/data-portraits development by creating an account on GitHub.
github.com
개요
기초 모델은 점점 더 방대하고 불투명한 데이터셋에서 훈련됩니다. 이러한 모델은 AI 시스템 구축의 핵심이 되었지만, 모델이 학습 중 특정 예시를 이미 접했는지 여부를 묻는 간단한 질문에 답하기 어려울 수 있습니다. 따라서 우리는 데이터 초상화(Data Portraits)의 광범위한 채택을 제안합니다. 이는 훈련 데이터를 기록하고 하위 검사 기능을 제공하는 인공물입니다. 먼저 이러한 인공물의 특성을 개략적으로 설명하고, 기존 솔루션이 투명성을 높이는 데 어떻게 사용될 수 있는지 논의합니다. 그런 다음 데이터 스케치에 기반한 솔루션을 제안하고 구현하며, 빠르고 공간 효율적인 쿼리 방식을 강조합니다. 우리의 도구를 사용하여 인기 있는 언어 모델링 코퍼스(The Pile)와 최근에 발표된 코드 모델링 데이터셋(The Stack)을 문서화합니다. 우리의 솔루션이 테스트 세트 누출 및 모델 표절에 관한 질문에 답하는 데 어떻게 도움이 되는지 보여줍니다. 우리의 도구는 경량화되고 빠르며 데이터셋 크기의 3%만 차지하는 오버헤드로 효율적입니다. 우리의 도구의 라이브 인터페이스를 dataportraits.org에서 제공하며, 데이터셋 및 모델 제작자들이 현재의 문서화 관행을 보완하는 데이터 초상화를 발표할 것을 권장합니다.
1. 소개
현대 AI는 큰 데이터셋에서 훈련된 큰 모델에 의해 주도되며, 이러한 모델이 확장됨에 따라 새로운 능력을 보여줍니다. 그러나 이러한 모델이 특정 예시를 학습 중에 접했는지 여부를 묻는 것은 자연스러운 질문입니다. 대규모, 불투명, 웹 스크랩된 데이터셋의 내용을 이해하는 것은 하위 모델 행동을 평가하는 데 중요합니다. 웹 데이터셋은 누출된 테스트 세트, 유해한 텍스트 또는 저품질 정보를 포함할 수 있으며, 이는 하위 모델에 영향을 미칩니다. 데이터셋 및 모델에 대한 문서화 인공물은 커뮤니티에 의해 제안되고 채택되었습니다. 그러나 대규모 데이터셋 검사를 지원하는 도구에 대한 연구는 부족합니다.
우리는 데이터 초상화의 광범위한 채택을 통해 기초 모델에 대한 기존 관행을 개선할 수 있다고 제안합니다. 데이터 초상화의 중요한 특성은 멤버십 추론, 즉 특정 예시가 데이터 수집의 일부였는지 여부입니다. 이러한 도구를 논의하면서 우리는 콘텐츠 제작자, 과학자 및 콘텐츠 소비자라는 세 가지 관점을 고려합니다. 제작자는 데이터셋에 자신의 콘텐츠(예: 저작권이 있는 코드)가 포함되어 있는지 알고 싶어합니다. 과학자는 테스트 세트 누출 또는 지식 암기를 평가하여 모델 행동을 이해하고자 할 수 있습니다. 콘텐츠 소비자는 모델이 기존 리소스를 표절하거나 인용하는지 알고 싶어할 수 있습니다.
우리의 기여는 두 가지입니다. 첫째, 멤버십 추론에 기반한 문서화 인공물을 요구하고, 기존 솔루션의 특성과 트레이드오프를 논의합니다. 그런 다음 그러한 인공물의 구현을 소개하고 이를 사용하여 널리 사용되는 대형 언어 모델(LLM) 코퍼스인 The Pile을 문서화합니다. 우리는 또한 최근의 코드 언어 모델링 코퍼스인 The Stack을 문서화합니다. 우리의 인공물은 데이터 스케치(압축된 데이터 뷰)를 사용하여 밀리초 단위의 지연 시간과 최소한의 계산 요구 사항을 가능하게 합니다. 우리의 도구와 라이브 데모를 dataportraits.org에서 공개합니다.
2. 배경 및 관련 연구
2.1 문서화 인공물
최근 많은 연구는 데이터셋과 모델을 문서화하는 추가 인공물을 요구했습니다. Gebru et al.는 데이터셋의 "동기, 구성, 수집 과정"을 문서화하는 Datasheet 인공물을 발표해야 한다고 주장했습니다. Mitchell et al.은 훈련된 모델을 위한 Model Cards라는 관련 인공물을 제안했습니다. 이러한 제안은 AI 커뮤니티 내에서 채택되었습니다. 새로운 모델은 이러한 인공물과 함께 발표되며, Huggingface와 같은 많은 리소스는 이제 문서화 인공물을 포함합니다. 우리는 데이터 초상화를 멤버십 질문에 답하는 보완적인 문서화 인공물로 봅니다.
2.2 대형 모델 및 웹 데이터
대규모 웹 스케일 코퍼스에서 훈련된 모델의 특성을 분석하는 관련 연구도 있습니다. Carlini et al.은 GPT-2가 훈련 코퍼스에서 민감하거나 개인 정보를 암기하고 유출할 수 있음을 보여주었습니다. 추가 연구에서는 암기 현상이 모델 확장과 함께 증가함을 보여주었습니다. GPT-3의 초기 구성에서는 특정 테스트 세트가 매우 큰 훈련 코퍼스에서 필터링되지 않는 버그가 있었습니다. 대형 언어 모델이 훈련 데이터의 일부를 암기하고 출력하는 것과 관련된 규범과 법적 선례는 아직 개발 중입니다. 일부 연구는 허용된 라이선스의 오픈 소스 코드 저장소를 수집했으며, 일반 크롤링 코퍼스의 데이터를 분석하여 언어 모델이 생성하기에 부적절한 콘텐츠를 포함하고 있는지 조사했습니다.
3. 데이터 초상화
우리는 멤버십 추론을 중심으로 한 데이터셋 문서화 도구의 바람직한 특성을 개략적으로 설명합니다.
- 빠름: 인공물은 저지연 프로그램 접근을 지원해야 합니다.
- 경량화: 인공물은 원본 데이터를 저장하는 것보다 많은 비용이 들지 않아야 합니다.
- 재분배 회피: 일부 데이터는 법적 또는 독점적 이유로 재배포할 수 없습니다.
- 로컬: 로컬 인공물은 비용이 많이 드는 외부 서비스를 필요로 하지 않습니다.
- 색인화: 도구는 일치가 발견된 컨텍스트를 나타내야 합니다.
- 유연한 일치: 유사성 검색에는 퍼지 매칭이 유용할 수 있습니다. PII나 암기와 관련된 경우에는 정확한 일치가 더 유용할 수 있습니다.
우리는 멤버십 추론을 위해 확률적 접근 방식을 사용합니다. 데이터 스케치는 데이터를 압축하고 근사적으로 보기 위해 오랫동안 사용되어 왔습니다. 우리의 인공물은 Bloom 필터를 사용하여 공간 효율적인 근사 멤버십 테스트를 구현합니다. Bloom 필터는 해시 기반 매칭을 사용하여 데이터 요소를 저장하는 대신 해시만 저장합니다. 우리의 솔루션은 Bloom 필터를 사용하여 원본 코퍼스의 약 3%만 차지하며 밀리초 단위의 쿼리 지연 시간을 가집니다.
4. 사례 연구
우리는 Bloom 필터를 기반으로 여러 데이터 초상화를 구축하고 사례 연구를 통해 시연합니다. 우리는 Pile과 The Stack을 기반으로 한 데이터 초상화를 구축하여, 표절 감지 및 테스트 세트 누출 질문에 답할 수 있는 능력을 입증합니다.
5. 분석
우리의 방법이 데이터를 이해하는 데 유용하다는 것을 보여줍니다. 우리는 Bloom 필터가 확률적 방법임에도 불구하고 유용성을 유지하고 있음을 보여줍니다. 우리의 접근 방식은 효율적이며 대규모 데이터셋을 분석하는 데 유용합니다.
6. 영향 및 한계
우리는 이 작업이 필드 구성원들이 멤버십 테스트 도구를 데이터셋 및 모델 문서화 인공물의 일부로 채택하도록 장려하기를 바랍니다. 우리의 도구는 대규모 언어 모델을 평가하는 데 있어 간단하고 투명한 방법을 제공합니다.
7. 결론 및 향후 작업
기초 모델에는 표절, 테스트 세트 및 개인 데이터 누출, 데이터 오염 및 데이터 출처와 같은 우려가 따릅니다. 우리는 기존의 문서화 관행만으로는 이러한 문제를 해결하기에 충분하지 않다고 주장하며, 모델을 훈련하는 데 사용된 데이터에 대한 멤버십 추론을 지원하는 데이터 초상화의 채택을 제안했습니다. 우리는 Bloom 필터를 기반으로 한 시간 및 공간 효율적인 버전을 설명하고 여러 데모를 호스팅합니다. 향후 작업에서는 유사한 효율적인 데이터 구조를 색인화 및 카운팅에 적용하는 것을 조사할 것입니다.
이 논문은 단일 데이터셋이나 벤치마크를 구성하지 않고, 우리는 단순히 데이터를 기록하고 효율적인 검사 도구를 제공함으로써 데이터 및 모델 문서화를 개선하는 것을 목표로 합니다.
4. Grounding via according-to Prompting
더보기이전 결과는 1) 인용 비율을 효율적으로 측정할 수 있고, 2) 더 많은 인용이 더 적은 환각과 상관관계가 있음을 보여줍니다. 다음으로, LLM이 학습 중에 본 신뢰할 수 있는 자원에서 직접 인용하도록 하여 지식 기반을 향상시키려고 합니다. 우리는 고품질 또는 신뢰할 수 있는 문서에서 복사된 문자열과 같은 유용한 기억된 콘텐츠에 접근하기를 희망합니다. 우리는 일반적인 작업 프롬프트(예: ODQA 질문)에 "응답에 위키백과 정보를 사용하세요"와 같이 기반을 유도하는 지시 구문을 추가하여 이러한 행동을 유도합니다. 우리는 이 전략을 '출처에 따른 프롬프트'라고 부릅니다. 우리의 실험은 추가 지시가 없는 프롬프트(즉, 널 프롬프트)와 출처에 따른 프롬프트로 생성된 텍스트의 QUIP-Score 변화를 측정합니다.
프롬프트가 기반을 증가시키고 감소시킬 수 있음을 확인하기 위해, 우리는 또한 기반을 반대로 하는 프롬프트(예: "응답에 [다른 소스]의 정보를 사용하세요" 또는 "위키백과의 정보를 사용하지 않고 응답하세요.")를 포함합니다. 이는 모델이 프롬프트의 길이가 아닌 프롬프트의 의미론적 의미 때문에 주어진 코퍼스에 기반을 두거나 두지 않을 수 있다는 가설을 테스트할 수 있게 해줍니다. 프롬프트가 결과에 영향을 미칠 수 있기 때문에(예: 구문 변경이 결과에 영향을 줄 수 있음), 우리는 이러한 프롬프트가 일관된 이점을 제공하는지 또는 단순히 프롬프트의 아티팩트인지 테스트하기 위해 여러 기반 및 반기반 프롬프트를 제공합니다(사용된 프롬프트 목록은 표 2 참조).

4.1 Datasets
우리는 LLM의 일관성을 테스트하고 기반이 주어진 데이터셋의 최종 작업 성능에 영향을 미치는지 확인하기 위해 다양한 데이터셋을 사용합니다. 그러나 출력의 기반을 가장 잘 측정하려면 모델 생성이 측정할 수 있는 많은 n-그램을 포함할 만큼 충분히 길어야 합니다. 따라서 우리는 장문 질문 응답(QA)을 테스트하고, 장문 출력을 잘 생성하지 않는 데이터셋(예: 단문 QA)에 대해서는 모델에게 답변과 해당 설명을 모두 생성하도록 요청하여 n-그램을 측정할 수 있게 합니다.
우리의 목적은 이러한 작업에서 최신 성능을 향상시키는 것이 아니라, 모델 출력의 기반을 분석하는 것입니다. 그러나 우리는 '출처에 따른 프롬프트'가 다른 프롬프트 기준선과 비교하여 경쟁력 있는 성능 또는 향상된 성능을 자주 달성한다는 점에 주목합니다. 이는 자연스럽게 기반이 되는 자료에서 질문에 답변할 수 있는 능력과 상관관계가 있기 때문입니다.
우리는 위키피디아의 사실적 지식을 목표로 하는 다음 데이터셋을 사용합니다: ELI5(Fan et al., 2019) (KILT Petroni et al. (2021b) 버전), Natural Questions(Kwiatkowski et al., 2019), TriviaQA (TQA) (Joshi et al., 2017), HotpotQA(Yang et al., 2018). 이 데이터셋들은 단문 및 장문, 단일 및 다중 홉 QA의 혼합을 포함합니다. 추가 세부 사항은 §A에 제공됩니다.
4.2 Models and Prompting
우리는 실험에서 OpenAI 모델(Wang et al., 2023), T5 기반 모델(T5를 언어 모델링에 맞춘 것, Raffel et al. 2020; Lester et al. 2021, FLAN-T5 Chung et al. 2022), GPT-J instruction tuned (Wang and Komatsuzaki, 2021), Koala (Geng et al., 2023) (Llama 변형, Touvron et al. 2023)을 포함한 다양한 모델을 테스트합니다. 이를 통해 (1) 오픈 소스 및 클로즈드 소스 모델 모두에 대한 결과, (2) 다양한 지시 조정 데이터를 사용하는 모델에 대한 결과, (3) 2억 2천만 개의 매개변수에서 1750억 개 모델에 이르는 모델들을 제공합니다. 우리의 실험은 모델에 프롬프트를 제공하는 것만 포함되며, 미세 조정은 포함되지 않습니다(목표는 이 모델들이 제로샷에서 무엇을 할 수 있는지 확인하는 것입니다).
단문 QA 데이터셋의 경우, 모델에 답변과 설명을 생성하도록 프롬프트를 제공한 후, 후자의 QUIP-Score를 측정합니다. 우리는 작은 모델(예: 150억 매개변수 미만)이 하나의 프롬프트만으로 답변과 설명을 구문 분석 가능한 형식으로 제공하는 지시를 따를 수 없다는 것을 발견했습니다. 따라서, 우리는 두 단계 프롬프팅을 사용합니다. 먼저 답변을 얻고, 그 다음 설명을 얻으며(사용된 경우 기반 프롬프트를 추가합니다). §B.2는 프롬프팅 세부 사항과 사용된 프롬프트의 전체 텍스트를 제공합니다.
5. Results
더보기먼저 우리는 ChatGPT에서 다양한 '출처에 따른 프롬프트'를 분석합니다. 그런 다음 널 프롬프트와 가장 성능이 좋은 '출처에 따른 프롬프트'를 다른 다양한 모델에서 테스트하여 추가 분석을 진행합니다. 표 2는 ChatGPT를 사용한 다양한 프롬프트에 대한 결과를 보여줍니다. 모든 '출처에 따른 프롬프트'가 널 프롬프트에 비해 QUIP-Score에서 유사하거나 개선된 성능을 보이는 명확한 경향이 있습니다. '반기반 프롬프트'의 QUIP-Score는 널 프롬프트(즉, 추가 텍스트가 없는 프롬프트)와 같거나 더 낮으며, '출처에 따른 프롬프트'보다 현저히 낮습니다.
놀랍게도, '출처에 따른 프롬프트'가 최종 작업 성능에서도 유사하게, 때로는 널 프롬프트보다 더 나은 성능을 보입니다(예: NQ에서 최대 6% 개선, HotpotQA에서 2.5% 개선). ELI5의 ROUGE-L에서는 이러한 경우가 아닌데, 이 메트릭은 위키백과와의 유사성보다는 Reddit과의 어휘적 유사성을 측정하기 때문입니다.
우리는 ChatGPT에서 얻은 이러한 결과를 바탕으로, 비용 문제로 인해 다음 실험에서 널 프롬프트와 최고의 기반 프롬프트(“이 질문에 대해 위키백과에 귀속될 수 있는 정보만 사용하여 응답하세요”)를 사용합니다.
5.1 Results from Other Models
우리는 표 3에 더 많은 모델에 대해 널 프롬프트에 비해 기반 프롬프트의 상대적인 차이를 보여주며, 이는 우리의 발견을 더욱 확인해줍니다(상대 수치 대신 절대 수치는 부록 B.2 참조). 예를 들어, Text-Davinci-003에 기반 프롬프트를 사용하면 널 프롬프트에 비해 QUIP-Score가 약 15% 향상되고 특정 작업에서는 5-20% 향상됩니다. 평가된 모든 모델에서 기반 프롬프트는 최종 작업 성능과 QUIP-Score 모두에서 5-105% 개선됩니다.
5.2 Impact of Model Size
모델 크기가 사전 학습 데이터에서 인용하는 능력에 영향을 미칠까요? 우리는 이 질문에 대해 QUIP-Score를 사용하여 답변하며, 그림 3은 다음과 같은 결과를 보여줍니다:
- 작은 모델의 경우, FLAN-T5 모델에서는 기반 프롬프트와 널 프롬프트 간 성능 차이가 없으며, OpenAI 모델에서는 기반 프롬프트가 오히려 더 낮은 성능을 보입니다.
- 그러나 큰 모델의 경우, OpenAI 모델과 FLAN-T5 모델 모두에서 널 프롬프트에 비해 기반 프롬프트가 훨씬 더 나은 성능을 보입니다.
- 결론적으로, 모델의 크기가 커질수록 사전 학습 데이터에서 인용하는 능력이 향상됩니다.
5.3 Impact of Entity Popularity
기억된 콘텐츠 생성에 영향을 미칠 수 있는 또 다른 요인은 질문에 언급된 엔티티의 인기도입니다(Kandpal et al., 2022; Carlini et al., 2023). 이전 연구에서는 질문과 답변의 엔티티가 동일한 구절에서 얼마나 자주 함께 나타나는지(공동 출현 횟수)가 작업 성능과 강하게 상관관계가 있음을 보여주었습니다(Kandpal et al., 2022). 우리는 그들의 코드와 데이터(Pile에서 가져옴)를 사용하여 QUIP-Score가 공동 출현 빈도와 상관관계가 있는지 탐구합니다.
공동 출현 횟수 간의 불균형으로 인해, 우리는 각 데이터셋과 공동 출현 빈도 상자에서 400개의 인스턴스(또는 사용 가능한 만큼)를 샘플링합니다. 우리는 ChatGPT에서 생성된 출력물을 사용하여 이러한 인스턴스에 대해 기반 프롬프트와 널 프롬프트 모두에 대해 QUIP-Score를 측정합니다. 그림 2는 QA 엔티티의 인기가 기반 프롬프트와 널 프롬프트 모두에서 QUIP-Score와 긍정적인 상관관계가 있음을 보여주며, 특히 기반 프롬프트에서 더 그렇습니다. 우리는 QA 엔티티가 자주 공동 출현할 때 모델이 위키피디아에서 정보를 더 잘 기억해낸다는 것을 발견했습니다.
5.4 Impact of Instruction Tuning
이러한 모델들이 요청 시 사전 학습 데이터를 기억해낼 수 있는 잠재적 이유 중 하나는 지시를 따르는 능력이 더 뛰어나기 때문입니다. 우리는 T5-11B와 FLAN-T5-11B를 비교한 그림 4에서 이 가설을 테스트합니다.
실험 결과, 지시 조정이 도움이 된다는 것을 알 수 있었습니다. T5-v1.1-Adapt의 경우 기반 프롬프트와 널 프롬프트 간의 QUIP-Score가 유사한 반면, FLAN-T5 모델은 널 프롬프트와 기반 프롬프트 간의 차이가 큽니다(약 2배 향상).
5.5 Qualitative Examples
그림 5는 다양한 모델의 출력 예시를 보여줍니다. '출처에 따른 프롬프트'로 질의했을 때, 모델은 위키백과에 나오는 더 큰 텍스트 덩어리를 생성합니다(보라색으로 표시됨). 텍스트가 기반되어 있더라도 출력 생성물이 질문에 대해 올바르다는 것을 의미하지 않는다는 점에 유의하는 것이 중요합니다. 예를 들어, TriviaQA 예제에서는 두 모델 모두 Smokey the Bear에 대해 잘못된 인용을 예측했지만, '출처에 따른 설명'이 위키피디아에 더 잘 기반되어 있었습니다.
6. Grounding to Other Corpora
더보기이전 실험에서 우리는 LLM이 요청 시 위키피디아에 기반할 수 있음을 보여주었습니다. 그러나 '출처에 따른 프롬프트'가 위키백과 도메인에만 한정되는 것일까요? 이 질문에 답하기 위해, 우리는 PubMed 기사와 2022년 세금 연도에 적용되는 미국 법률 세법으로 두 개의 DATA PORTRAIT를 추가로 구축했습니다. 그런 다음 이러한 배경 지식이 유용할 데이터셋에서 평가하고, 이전 위키백과 실험과 유사하게 다운스트림 작업 성능과 QUIP-Score를 평가합니다.
Datasets
우리는 PubMed에 기반한 MultiMedQA 벤치마크 스위트(Singhal et al., 2022)에서 다음 데이터셋을 사용합니다:
- PubMedQA(Jin et al., 2019): PubMed 초록을 읽고 이해하는 작업.
- MedQA(Jin et al., 2020): 미국 의사 면허 시험에서 나온 여러 선택형 질문으로 구성됨.
- MedicationQA(Abacha et al., 2019): 환자 약물에 대한 오픈 도메인 질문.
이 두 가지는 직접적으로 PubMed에서 출처를 가져오지는 않았지만, PubMed에 있는 정보가 포함될 가능성이 큽니다. PubMedQA에서 모델에 초록을 제공하지 않고, 닫힌 책 형식으로 평가하여 모델 매개변수에서 인용된 내용을 측정합니다.
법률 도메인에서는 자연어 추론을 사용하여 평가되는 세금 사례로 구성된 SARA 데이터셋(Holzenberger et al., 2020)을 사용합니다.
Results
표 4에서 ChatGPT의 결과는 '출처에 따른 프롬프트'가 최종 작업 성능과 QUIP-Score를 개선함을 보여줍니다. SARA에서는 QUIP-Score가 세 배 이상 증가하면서 성능도 약간 향상되었습니다. 의료 도메인에서는 PubMed에 기반한 작업 성능이 약간 향상되었으며, 모든 데이터셋에서 QUIP-Score가 향상되었습니다.
7. 논의 및 향후 영향
더보기우리의 결과는 LLM이 훈련 데이터에 있는 인간 작성 소스를 더 많이 인용하도록 프롬프트를 통해 유도할 수 있음을 강하게 시사합니다. 이 발견은 우리가 고려한 작업뿐만 아니라 출처 기반이 중요한 다양한 작업 공간에 강력한 영향을 미칩니다. 우리는 '출처에 따른 프롬프트' 전략이 검색 증강을 포함한 다른 LLM 기반 방향과 직교하며, '출처에 따른 프롬프트'가 간단하고 일반적으로 기반과 작업 성능을 모두 향상시키기 때문에 앞으로의 연구에서 이 접근 방식을 함께 시도해보기를 권장합니다.
8. 결론
더보기대형 언어 모델은 사실적 사전 학습 데이터가 많음에도 불구하고 환각, 즉 잘못된 정보를 생성하는 문제를 겪습니다. 이 문제를 완화하기 위해, 우리는 언어 모델에게 사전 학습 코퍼스에 기반하여 출력을 생성하도록 요청하는 '출처에 따른 프롬프트'를 제안했습니다. 모델이 이 목표를 달성하는 정도를 정량화하기 위해, 사전 학습 코퍼스에서 모델 생성의 몇 퍼센트가 정확한 인용으로 존재하는지를 효율적이고 빠르게 측정하는 새로운 메트릭인 QUIP-Score를 도입했습니다. 우리는 다양한 도메인과 코퍼스에서 '출처에 따른 프롬프트'가 QUIP-Score를 크게 향상시키고, '반기반 프롬프트'는 QUIP-Score를 감소시킨다는 것을 보여주었습니다. 또한 QUIP-Score가 질문에서 엔티티의 인기와 모델 크기에 따라 증가한다는 것을 보여주었습니다. 우리는 이 연구가 LLM의 기억의 긍정적인 측면에 더 많은 관심을 불러일으키고, LLM이 사전 학습 데이터에 기반하도록 이해하는 데 더 많은 연구를 장려하기를 바랍니다.
9. 한계
더보기우리의 제안된 메트릭은 정확한 어휘 일치만을 고려하며, 다른 유형의 기반 진술은 놓치기 때문에, QUIP-Score를 소스 자료에서 인용으로 정의된 기반의 하한으로 간주합니다. QUIP-Score는 또한 DATA PORTRAIT에 특화되어 있어, 초상화에 포함된 n-그램의 양이 점수에 영향을 미칩니다. 우리는 이 메트릭을 일반화하는 것을 미래 연구에 맡기며, 우리의 연구는 동일한 초상화로 두 가지 프롬프트를 비교하는 데 중점을 둡니다.
또한 ChatGPT와 같은 비공개 모델의 사전 학습 데이터와 분석에 사용된 위키백과 버전 간의 불일치 가능성을 인식하고 있지만, 위키백과가 완전히 정적이지는 않더라도 이 지식 소스의 상당 부분은 짧은 기간 동안 일관성을 유지하므로 큰 문제가 되지 않을 수 있습니다. 또한, ChatGPT와의 결과는 GPT-J와 같은 정확한 사전 학습 데이터를 가진 모델과 비교했을 때 유사합니다.
Appendix
더보기A. Dataset Details
ELI5는 "Explain Like I’m 5"(Fan et al., 2019)로, 서브레딧 r/ELI5에서 사용자 질문과 답변으로 구성된 장문 QA 데이터셋입니다. 우리는 원본의 비기반 질문이 필터링된 "기반" 서브셋인 KILT 버전(Petroni et al., 2021a)의 개발 세트를 사용하여 연구 질문에 더 적합한 평가를 수행합니다.
Natural Questions (NQ)(Kwiatkowski et al., 2019)는 실제 구글 검색에서 수집된 단문(< 5단어) QA 데이터셋입니다. NQ에 대한 프롬프트와 관련된 이전 연구와 비교하기 위해 전체 개발 세트를 평가합니다.
TriviaQA (TQA)(Joshi et al., 2017)는 퀴즈 웹사이트에서 질문과 답변 쌍을 스크랩하여 수집한 후, 위키백과 구절과 일치시킨 데이터셋입니다. 이전 연구를 따라 필터링된 개발 세트(7천 개 인스턴스)를 사용합니다.
HotpotQA(Yang et al., 2018)는 두 단계의 추론이 필요한 다중 단계 단문 질문 응답 데이터셋입니다. 아마존 메커니컬 터크를 통해 크라우드소싱된 질문과 답변에서 수집되었습니다. 전체 개발 세트를 사용합니다.
B. All Results
B.1 표 3의 SOTA 성능 출처 SOTA 제로샷 결과는 각각 LLaMA 33B 및 65B(Touvron et al., 2023), PaLM 540B(Wang et al., 2022a), BART(Su et al., 2022)에서 가져왔습니다. 검색 증강된 SOTA는 NQ, TriviaQA 및 HotpotQA의 경우 Izacard et al. (2022), ELI5의 경우 Su et al. (2022)의 결과를 보여줍니다.
B.2 According-To vs Null에 대한 추가 모델 표 3에 공간 문제로 포함되지 않은 모든 모델의 결과를 보여줍니다.
단문 QA 프롬프트 단문 QA 데이터셋의 경우, 모델이 답변과 설명을 구문 분석 가능한 형식으로 생성하도록 다음 프롬프트를 질문 앞에 추가합니다:

Prompt for ELI5 for smaller models.
T5-v1.1-Adapt 및 GPT-J-Instruct를 ELI5에서 평가할 때, 정상적인 널 및 기반 프롬프트 끝에 "Answer:"를 추가합니다. 그렇지 않으면 모델이 매우 짧거나(5단어 미만) 의미 없는 응답을 출력하기 때문입니다. 이 추가로 모델은 정상적인 유창한 텍스트를 생성합니다.
C. Conventional N-Gram Metrics
sacrebleu와 같은 도구 키트는 여러 n-그램 메트릭을 구현합니다(Post, 2018). 그러나 이러한 도구는 일반적으로 파이썬 세트 및 딕셔너리와 같은 기존 데이터 구조를 사용합니다. 이는 매우 큰 참조(즉, 위키백과 전체)에 대한 n-그램 메트릭 측정에는 적합하지 않습니다. 표 6에서 위키백과의 25자 n-그램 중 약 0.07%인 약 1억 개의 n-그램 샘플의 여러 데이터 구조 크기를 비교합니다. 일반적인 CPython 세트 또는 딕셔너리 구현은 데이터 요소(즉, 문자 n-그램 또는 문자열)에 대한 포인터의 해시 테이블을 사용합니다. 해시 테이블 백업 배열과 문자열 데이터 요소를 저장하려면 상당한 메모리가 필요합니다(11,107 MiB).
이것은 해시 테이블만 저장하고 데이터 요소는 저장하지 않아 해시 충돌에 대한 오탐을 도입하여 최적화할 수 있습니다(이는 k = 1 해시 함수를 사용하는 블룸 필터와 유사함). 문자열의 복사본 대신 원본 텍스트의 포인터(참조)만 저장할 수도 있습니다. 이러한 옵션은 우리의 매개변수로 선택한 최적의 블룸 필터보다 여전히 큽니다. 샘플 데이터에서 이는 약 163 MiB의 메모리를 소비합니다. 이러한 저장 비용을 외삽하면, 단순하고 최적화되지 않은 파이썬 세트 또는 딕셔너리를 사용하면 모든 n-그램을 저장하는 데 약 1.5TB의 메모리를 소비할 것으로 보입니다.
이 측정값은 단일 n-그램 폭에만 해당된다는 점에 유의하십시오. QUIP-Score를 여러 폭의 n-그램을 저장하는 메트릭과 비교하면 메모리 사용량이 더 증가할 수 있습니다.
D. Prompts for Non-Wikipedia Datasets
우리는 위키백과 섹션에서 사용한 것과 같은 스타일의 프롬프트를 사용하되, 작업의 형식에 맞게 수정합니다. 예를 들어, SARA 데이터셋에서는 ChatGPT가 매 질문에 대해 추론을 예측하지 않도록 추가적인 문구를 제공하여 예측을 보다 균형 있게 만듭니다.
SARA
You are a highly intelligent & complex legal statutory entailment system that checks whether a particular judgement holds for a particular case in the U.S. legal tax code. You take the ruling of a legal situation and respond with a reply of contradiction or entailment, along with a corresponding two paragraph explanation. Your answer should be short - only contradiction or entailment. Be sure to verify that the entailment is 100% correct, otherwise choose contradiction.
Your output format should be the answer, then a semicolon, then the verbose explanation.
Premise: {Insert Text Background}
Hypothesis: {Insert Question}
Fill in the following:
ANSWER HERE; EXPLANATION HEREPubMed
단문 QA에 대해 일반적으로 지정된 프롬프트와 동일한 프롬프트를 사용하되, '\n\nAccording to PubMed,'를 기반 프롬프트로 사용합니다.
MedQA
단문 답변 시작 프롬프트와 동일한 프롬프트를 사용하되, 다음과 같은 변경 사항을 포함합니다:
\n\nAccording to PubMed the multiple choice answer is:\n
MedicationQA
질문 전에 프롬프트를 추가하지 않고 기반 프롬프트만 추가합니다(단문 형식이 아님). PubMedQA와 동일한 기반 프롬프트를 사용합니다.
E. Computational Resources
우리는 OpenAI와의 실험을 위해 모델 API를 사용하고, 로컬 모델과의 실험을 위해 1개의 A100 GPU를 사용합니다. 각 실험은 각 데이터셋에 대해 약 1시간 이내에 완료되었습니다.
ChatGPT 요약
더보기연구 배경 및 목표:
대형 언어 모델(LLM)은 사실 데이터를 사전 학습하면서도 허위 정보를 생성하는 경향이 있습니다. 이 연구는 저널리즘에서 사용되는 "출처에 따르면"과 같은 장치를 이용해 LLM이 사전 학습 데이터에서 인용을 더 많이 하도록 유도하여 허위 정보 생성을 줄이고자 합니다.
주요 기여:
- QUIP-Score:
- 새로운 평가 메트릭인 QUIP-Score(Quoted Information Precision)를 제안하여, 모델이 생성한 응답이 사전 학습된 텍스트 코퍼스와 얼마나 겹치는지를 측정합니다.
- 사전 학습 데이터 인용 유도:
- LLM이 사전 학습된 데이터에서 직접 인용을 더 많이 하도록 유도하는 프롬프트 기법을 탐구합니다. 예를 들어, "Wikipedia에 따르면"과 같은 구문을 추가하여 모델이 Wikipedia에서 인용하도록 유도합니다.
실험 및 결과:
- 데이터셋: Wikipedia, PubMed, U.S. 법률 세법 코드.
- 모델: 다양한 LLM(오픈소스 및 클로즈드소스)을 사용하여 실험.
- 실험 결과: 프롬프트를 사용하여 모델이 사전 학습된 데이터에서 인용을 더 많이 하도록 유도하면, QUIP-Score가 5-105% 증가하면서 종단 작업 성능도 종종 향상되었습니다.
세부 내용:
- QUIP-Score의 유효성:
- QUIP-Score는 n-그램 중복률을 기반으로 하여, 사전 학습 코퍼스와의 중복 정도를 효율적으로 측정합니다.
- 실험 결과, QUIP-Score가 높을수록 인용 빈도가 증가하고, 허위 정보 생성이 감소하는 경향이 나타났습니다.
- 프롬프트 기법:
- "Respond by using information from Wikipedia in your response"와 같은 지시문을 추가하여, 모델이 응답에서 Wikipedia를 인용하도록 유도했습니다.
- 다양한 프롬프트를 사용하여 모델의 응답을 테스트한 결과, 지시문이 없는 경우보다 인용 빈도와 응답의 정확성이 향상되었습니다.
- 모델 크기와 성능:
- 모델 크기가 클수록 프롬프트를 통한 인용 유도 효과가 더 크게 나타났습니다.
- 작은 모델에서는 프롬프트의 효과가 제한적이었지만, 큰 모델에서는 프롬프트를 통해 인용 빈도와 응답 정확성이 크게 향상되었습니다.
- 다른 도메인에 대한 확장:
- PubMed 및 U.S. 법률 세법 코드와 같은 다른 도메인에서도 프롬프트를 통해 인용 빈도를 높일 수 있음을 확인했습니다.
- PubMedQA, MedQA, MedicationQA, SARA와 같은 데이터셋에서도 프롬프트 기법을 적용하여 유사한 성능 향상을 보였습니다.
결론:
- 사전 학습 데이터 인용: LLM이 사전 학습된 데이터에서 직접 인용을 더 많이 하도록 유도하면, 허위 정보 생성을 줄이고 응답의 신뢰성을 높일 수 있습니다.
- QUIP-Score: 인용 빈도를 측정하는 데 효율적인 도구로, 사전 학습 코퍼스와의 중복 정도를 정량화하여 모델의 성능을 평가할 수 있습니다.
- 미래 연구 방향: 이 연구는 LLM의 메모리 활용을 긍정적으로 활용하는 방향을 제시하며, 향후 연구에서는 다른 도메인과의 결합을 통해 더 다양한 응용 분야에서의 성능 향상을 탐구할 필요가 있습니다.
https://arxiv.org/pdf/2305.13252
반응형