-
[CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster논문 리뷰 2026. 3. 17. 19:15더보기
Zhang, Qizhe, et al. "Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025.
문제점: 지나치게 많은 visual token
VLM의 입력 시퀀스에서 visual token이 차지하는 비중이 매우 높은데, 거의 90%에 달한다. 이로 인해 계산 복잡도(computational complexity)와 추론 비용(inference cost)이 급격히 증가한다.
일부 연구들은 입력 이미지 해상도를 높여 성능을 개선하려 했지만, 이 역시 visual token의 개수를 증가시켜 오히려 계산 비용을 키우는 결과를 낳았다. 특히 Video-LLaVA 같은 비디오 기반 모델에서는 이 문제가 더 심각하다.
FastV의 접근 방식: 불필요한 visual token 선택적 제거
VLM의 추론 비용을 줄이기 위해, FastV는 VLM 내부 LLM의 정보 흐름(information flow)을 분석했다. 그 결과, 비효율적인 visual attention 현상을 발견했는데, LLM의 깊은 레이어(layer 2 이후)에서는 visual token이 textual token에 비해 현저히 적은 attention을 받는다는 점이다. 이는 visual token에서 텍스트로 전달되는 유용한 정보가 적다는 뜻이며, 일부 visual token을 제거해도 성능 저하가 크지 않다는 가능성을 보여준다.
이에 따라 FastV는 layer 2 이후의 attention score를 기준으로 visual token의 중요도를 평가하고, 하위 R%를 pruning하는 방법을 제안했다. 이를 통해 visual token의 중복성을 줄이고 추론 효율을 개선할 수 있었다.
이후 여러 후속 연구들 [61, 65]이 등장하며, LLM의 text-visual attention을 활용해 visual token을 선택적으로 제거하는 다양한 방법이 시도되었다.
한계점
하지만 FastV는 visual token pruning의 가능성을 잘 보여주었음에도 불구하고, text-visual attention에 기반한 pruning 방식은 그다지 효율적이지 않다.
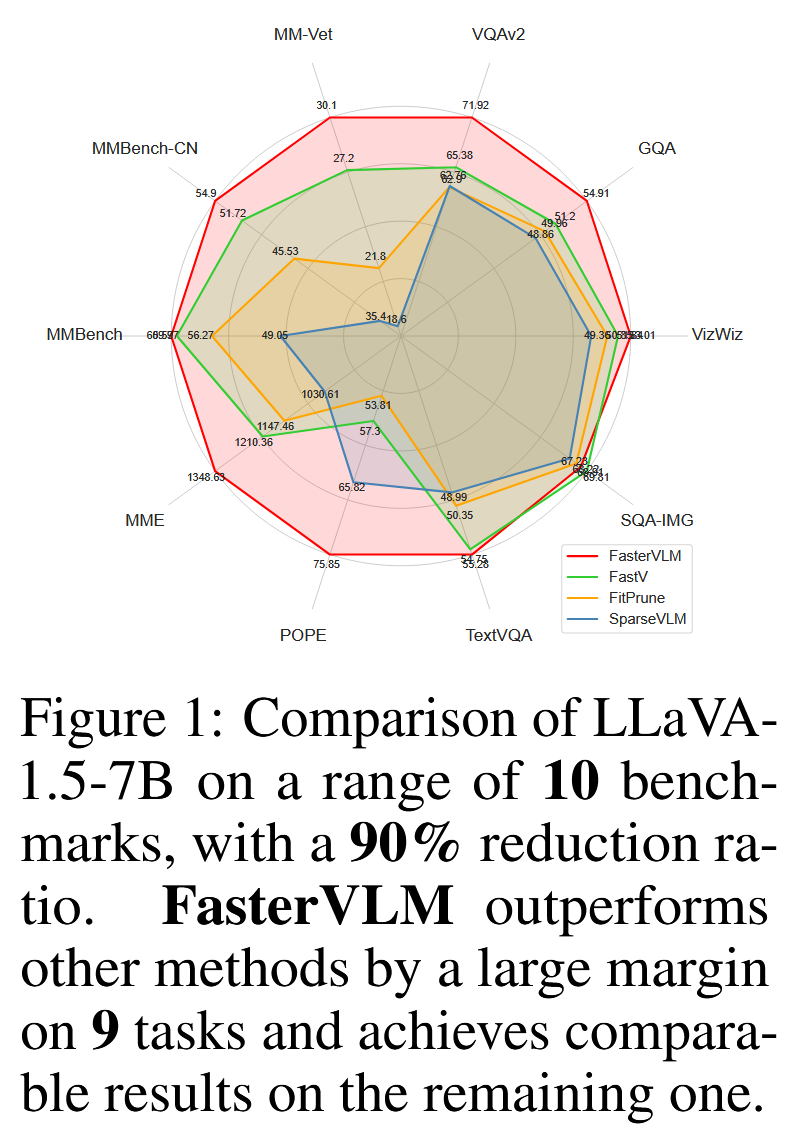
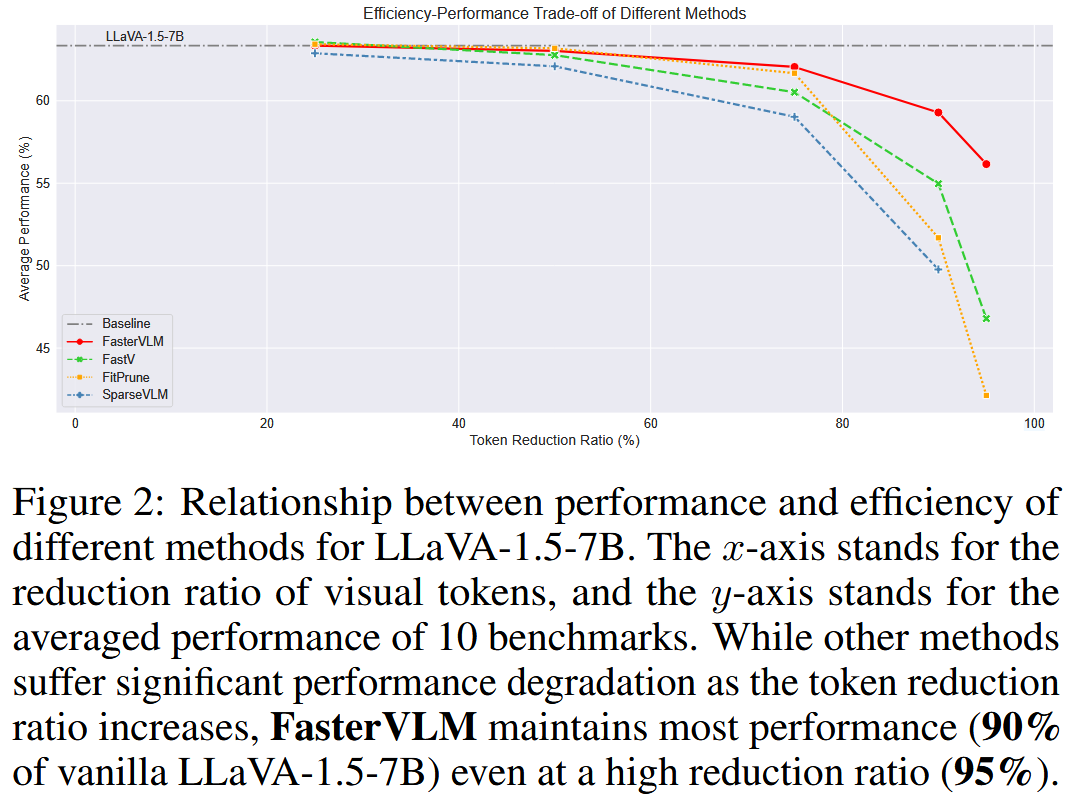
Fig. 2에 따르면, visual token을 줄일수록 대부분의 VLM 모델 성능은 급격히 저하된다. FastV는 그나마 성능 저하가 완만한 편이지만, 여전히 한계가 존재한다.본 논문에서는 VLM 내부의 LLM에서 사용되는 text-visual attention이 실제 visual token의 중요도를 제대로 반영하지 못한다는 점을 발견했다. 즉, 각 visual token에 할당된 attention weight가 그 token의 실제 중요성과 일치하지 않는다는 것이다.
이러한 문제는 두 가지 관점에서 설명할 수 있다: attention shift와 attention dispersion.
Attention Shift
먼저, attention shift란 textual attention이 visual token 시퀀스의 뒷부분에 치우쳐 집중되는 현상을 의미한다. 이는 중요한 시각 정보를 앞쪽에서 놓치는 결과를 낳는다. 논문에서는 이러한 현상이 두 가지 요인 (1) LLM의 단방향 정보 흐름(unidirectional information flow), (2) token 간 상대적인 위치 관계(relative positional relationship)에서 비롯된다고 분석한다.

x축은 이미지 토큰의 인덱스, y축은
- [CLS] 토큰이 해당 이미지 토큰에 얼마나 주의를 기울이는지를 나타내는지,
- 다른 이미지 토큰들이 서로에게 얼마나 주의를 기울이는지를 나타내는지,
- 텍스트 토큰들이 이미지 토큰에 얼마나 주의를 기울이는지
- 마지막 토큰이 이미지 토큰에 얼마나 주의를 기울이는지
Attention Dispersion
다음으로, attention dispersion은 LLM 내부의 attention 분포가 visual encoder에 비해 덜 집중되어 있는 현상을 말한다. 즉, LLM에서는 더 많은 visual token이 상대적으로 높은 attention score를 받지만, 가장 높은 값 자체는 낮은 경향을 보인다. 이는 multi-modal projector가 시각 정보와 텍스트 임베딩을 정렬해주긴 하지만, 여전히 두 modality 간에는 정렬의 간극(alignment gap)이 존재하기 때문이라고 설명한다. 이로 인해 shallow layer에서 noisy한 text-visual attention이 발생하고, 중요 visual token을 제대로 구분하지 못하게 된다.

- [CLS] Attention Map: 시각적 인코더의 [CLS] 토큰이 이미지의 각 패치(토큰)에 얼마나 주의를 기울이는지를 히트맵으로 나타낸 것이다.
- Last Attention Map: 언어 모델의 마지막 토큰이 시각적 토큰에 얼마나 주의를 기울이는지를 나타낸 것이다.
- [CLS] Attention Distribution: [CLS] 토큰이 각 시각적 토큰에 부여하는 주의 점수의 분포를 막대그래프로 나타낸 것이다. -> 대부분의 시각적 토큰이 매우 낮은 주의 점수를 받고, 소수의 토큰만이 높은 점수를 받는다
- Last Attention Distribution: 언어 모델의 마지막 토큰이 시각적 토큰에 부여하는 주의 점수의 분포를 막대그래프로 나타낸 것이다. -> 어텐션 점수가 더 분산되어있음
Attention Shift & Attention Dispersion 구현 코드
모델에 실제로 들어가는 입력:
- input_ids: 텍스트 + image placeholder가 반영된 token sequence
- image_tensor: 전처리된 이미지 tensor
- image_sizes: 원본 이미지 크기
두 코드 모두 model.generate(..., output_attentions=True, return_dict_in_generate=True)를 호출합니다. 그래서 일반 생성 결과뿐 아니라 attention도 함께 받습니다. 추가로 cls_attn 혹은 cls_attns라는 별도 값도 같이 반환받고 있습니다.
제안 방법: FasterVLM
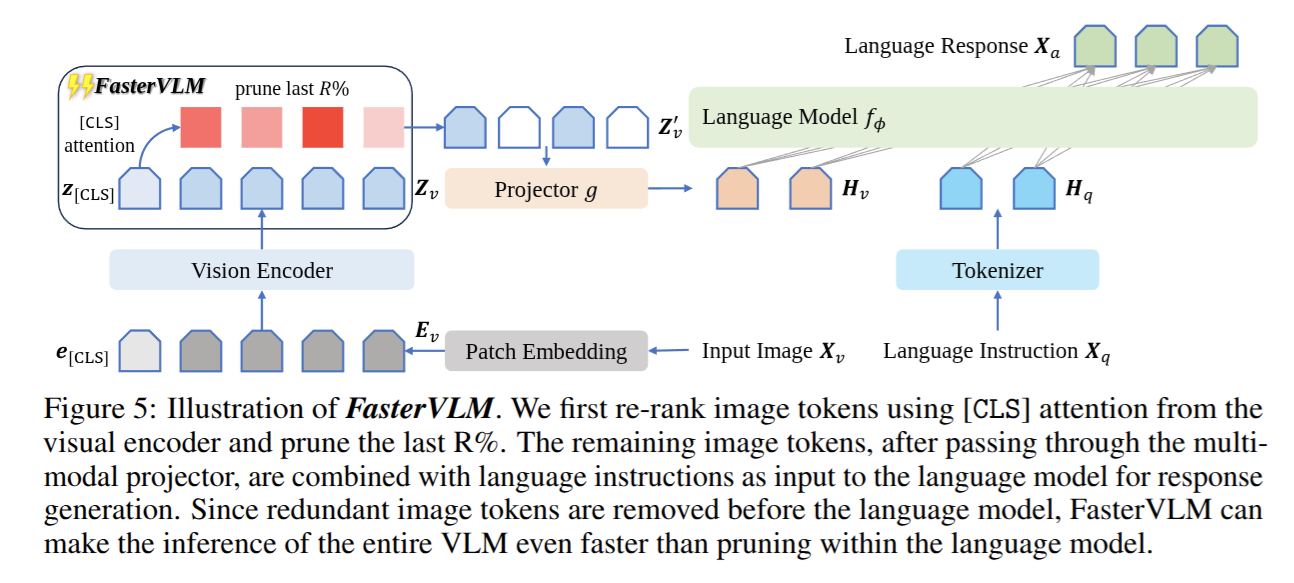
이 문제를 해결하기 위해 저자들은 FasterVLM이라는 간단하면서도 효과적인, training-free visual token pruning 방법을 제안한다. 핵심 아이디어는 다음과 같다:
- image encoder의 [CLS] token이 갖는 attention weight를 기반으로 각 visual token의 중요도를 평가한다.
- 중요도가 낮은 visual token은 LLM에 입력되기 전에 제거하여, 전체 추론 속도를 크게 개선한다.
흥미롭게도, [CLS] attention은 attention shift 현상을 보이지 않았다. 이는 image encoder의 global attention 메커니즘 덕분이다. 또한 text-visual attention에 비해 [CLS] attention은 더 집중된 형태를 띠기 때문에, visual token의 중요도를 평가하는 지표로서 더욱 적합하다고 판단된다.
효과
ViT 기반 모델에서 종종 나타나는 attention map의 artifact 문제(주변과 지나치게 유사한 영역에 attention이 몰리는 현상) 또한 FasterVLM으로 인해 개선된다. 기존 방식은 이런 artifact를 잘 구별하지 못해 중요한 글로벌 정보를 놓쳤지만, FasterVLM은 [CLS] attention을 통해 이러한 글로벌 정보를 담은 visual token을 효과적으로 식별하고 보존할 수 있었다.
또한 FasterVLM은 LLaVA-1.5, LLaVA-NeXT, Video-LLaVA 등 다양한 VLM에 쉽게 적용 가능하며, 추가 학습 없이 최대 95%의 visual token을 제거하면서도 성능을 90% 이상 유지하는 뛰어난 효율을 보였다.
코드
https://github.com/Theia-4869/FasterVLM/
GitHub - Theia-4869/FasterVLM: Official code for paper: [CLS] Attention is All You Need for Training-Free Visual Token Pruning:
Official code for paper: [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster. - Theia-4869/FasterVLM
github.com
참고
https://dusruddl2.tistory.com/120
[25’ ICCV] [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster
# Introduction요즘 대세인 ChatGPT, Gemini, Claude 같은 AI는 텍스트와 이미지를 함께 이해할 수 있는 대형 비전-언어 모델(VLM) 덕분에 점점 더 똑똑해지고 있다. 그런데 흥미로운 사실이 하나 있다. 문제
dusruddl2.tistory.com
반응형'논문 리뷰' 카테고리의 다른 글